Don’t drop your samples! Coherence-aware training benefits Conditional diffusion
CVPR 2024 (Highlight)
Abstract
Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.
Generated Samples









Varying the Coherence

Top prompt:
"a raccoon wearing an astronaut suit. The racoon is looking out of the window at a starry night; unreal engine, detailed, digital painting, cinematic, character design by pixar and hayao miyazaki unreal 5, daz, hyperrealistic, octane render"
Bottom prompt:
"An armchair in the shape of an avocado"
Convergence towards the unconditional distribution
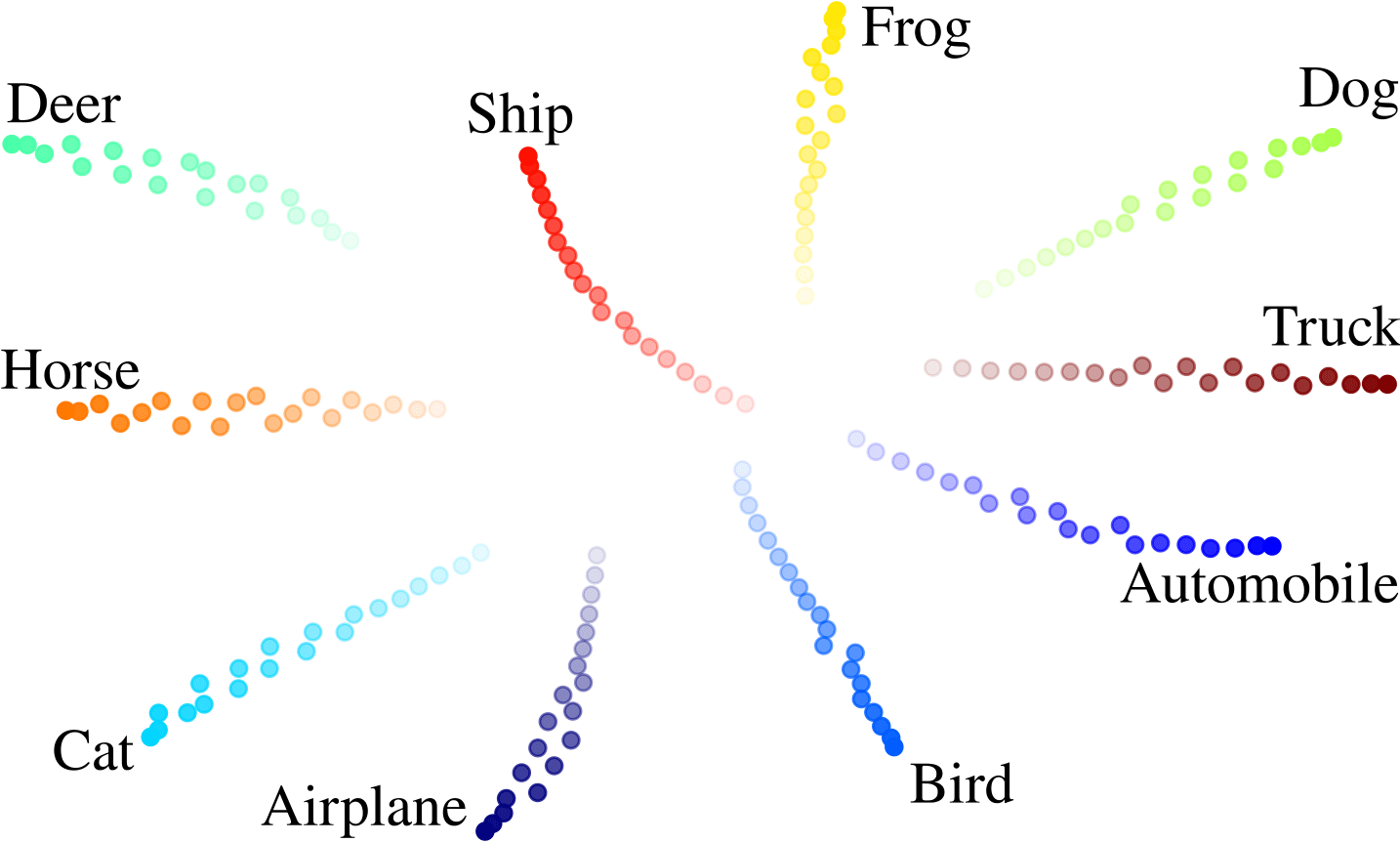

When varying the coherence towards zero, we observe that the model converges to the same unconditional model. In the CIFAR embedding space (left) we observe that the embeddings converge to the same point. On Imagenet (right), we see that no matter the label, the output image becomes the same as we decrease the coherence.
TextRIN: A new text-to-image architecture
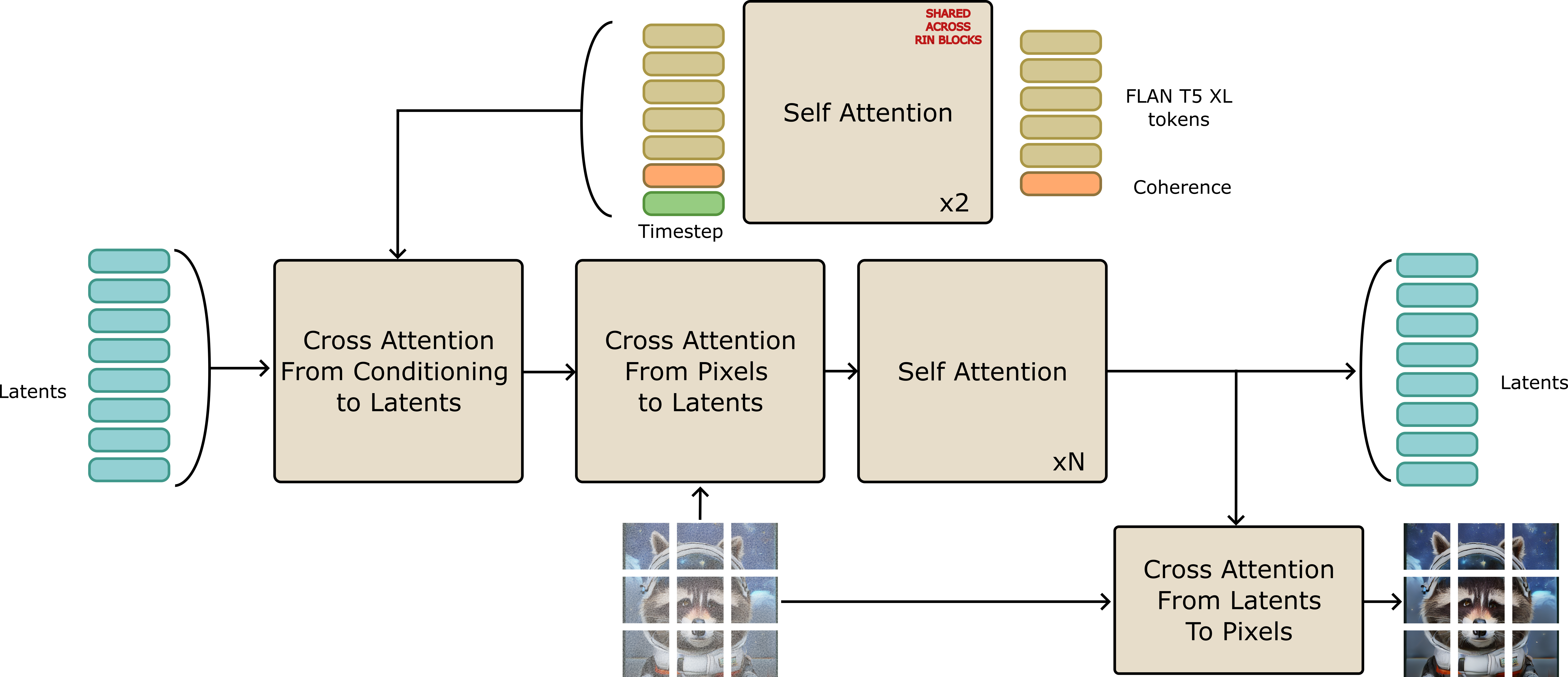
We propose a new text-to-image architecture based on the RIN (Jabri et al, 2023). Similar to RIN, our architecture has the advantage to do most of the computation in a restricted latent space, which allows for efficient sampling and training. However, we introduce a new module, the TextRIN, that conditions the RIN on the input text. It also incorporates the coherence score between the input text and the target image. This allows the model to generate images that respect the input text better.
Demo
Poster
Video
Bibtex
@article{dufour2024dont,
title={Don’t drop your samples! Coherence-aware training
benefits Conditional diffusion},
author={Dufour, Nicolas and Besnier, Victor and Kalogeiton, Vicky and
Picard, David},
booktitle={CVPR},
year={2024},
}
Acknowledgements
This work was supported by ANR project TOSAI ANR-20-IADJ-0009, and was granted access to the HPC resources of IDRIS under the allocation 2023-AD011014246 made by GENCI. We would like to thank Vincent Lepetit, Romain Loiseau, Robin Courant, Mathis Petrovich, Teodor Poncu and the anonymous reviewers for their insightful comments and suggestion.