Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation
Abstract
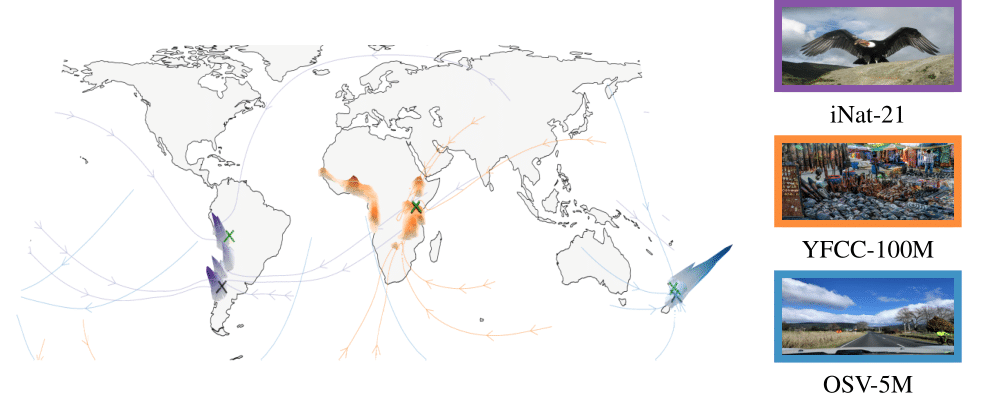
Introducing the first generative geolocation method based on diffusion and flow matching! We learn the relationship between visual content and location by denoising random locations conditionally to images.
➜ New SOTA for visual geolocation on OpenStreetView-5M, YFCC-100M, and iNat-21
➜ Generate global probability density maps and quantify localizability
➜ Introduce the problem of probabilistic visual geolocation
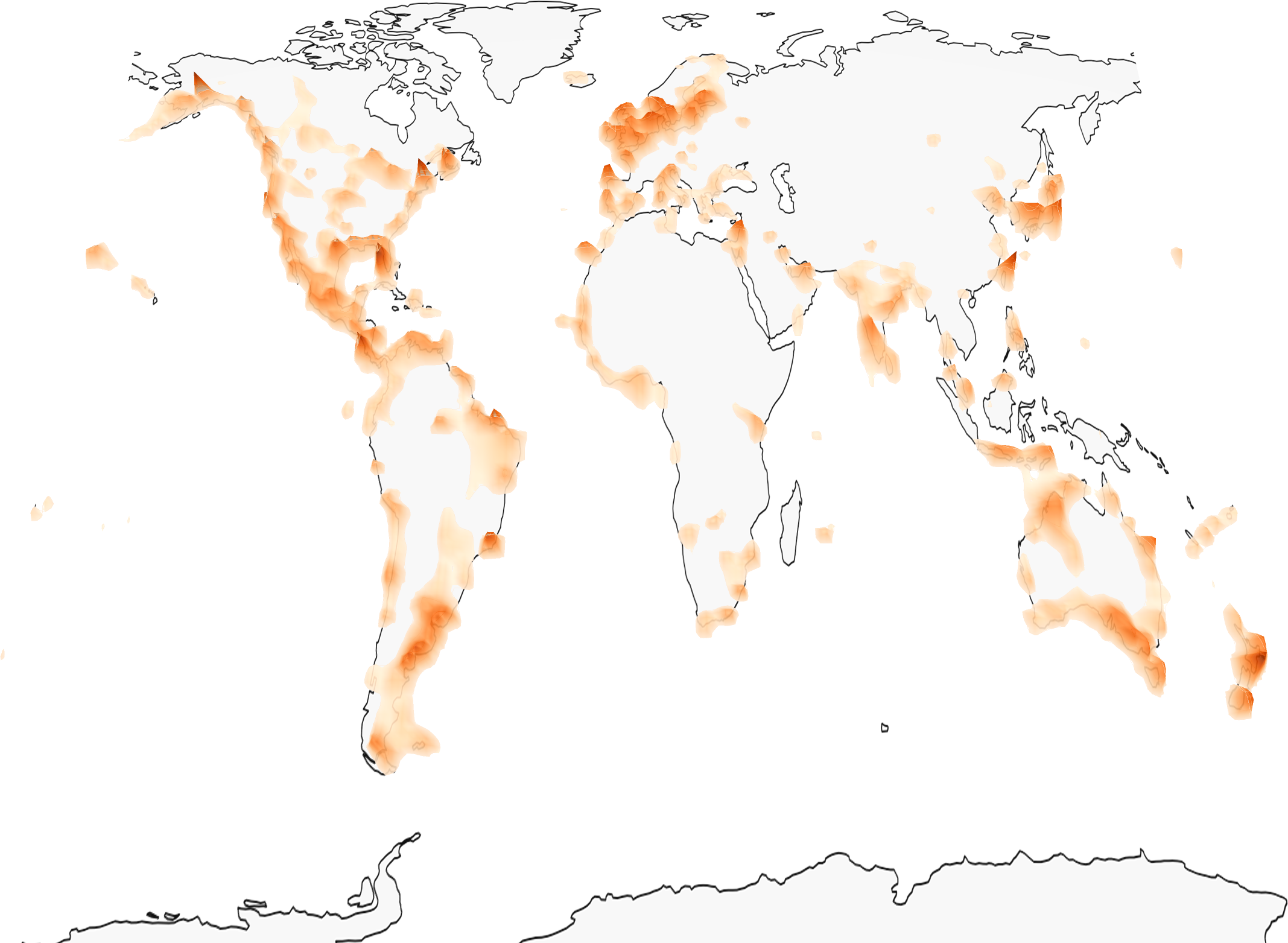
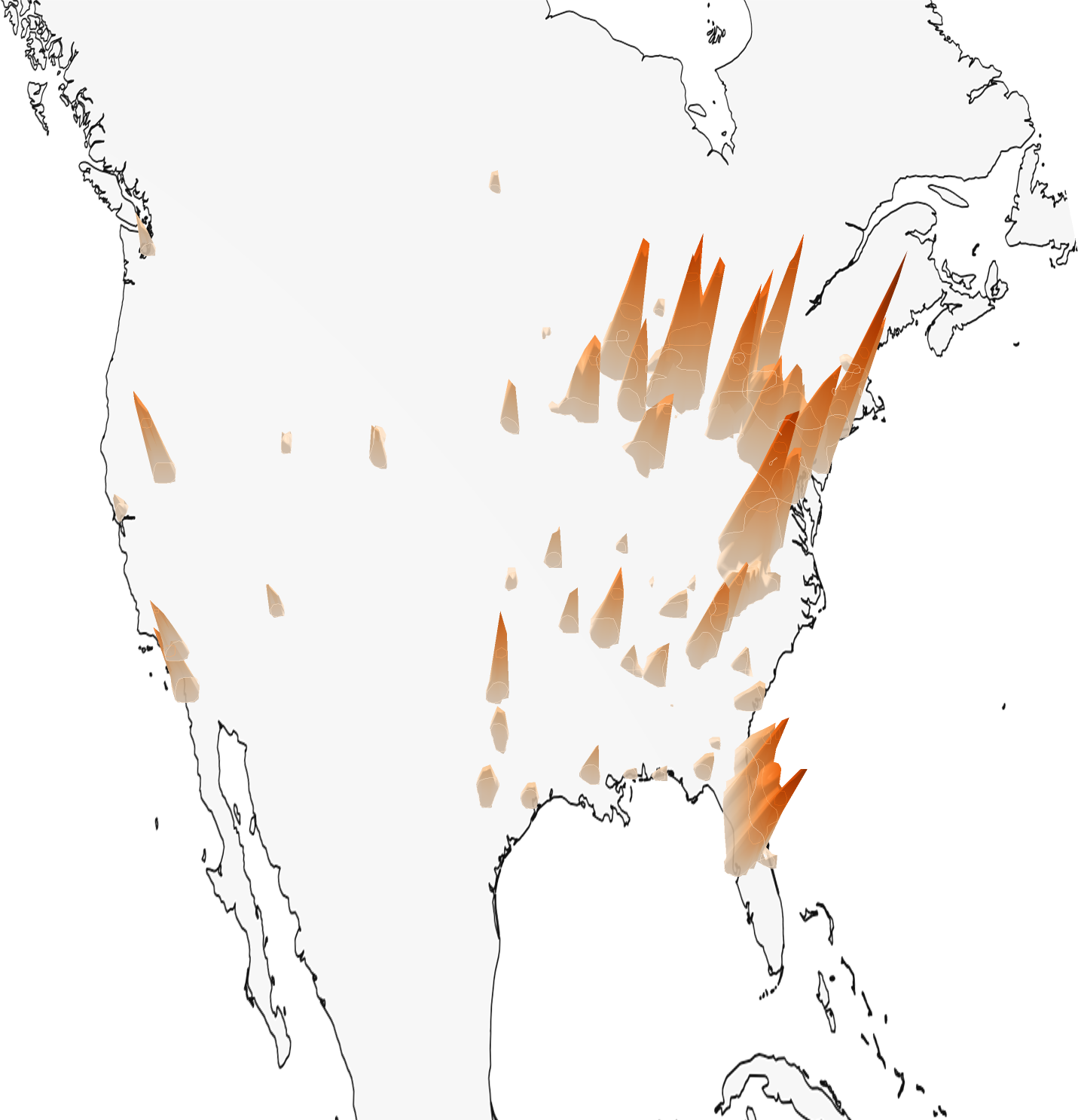
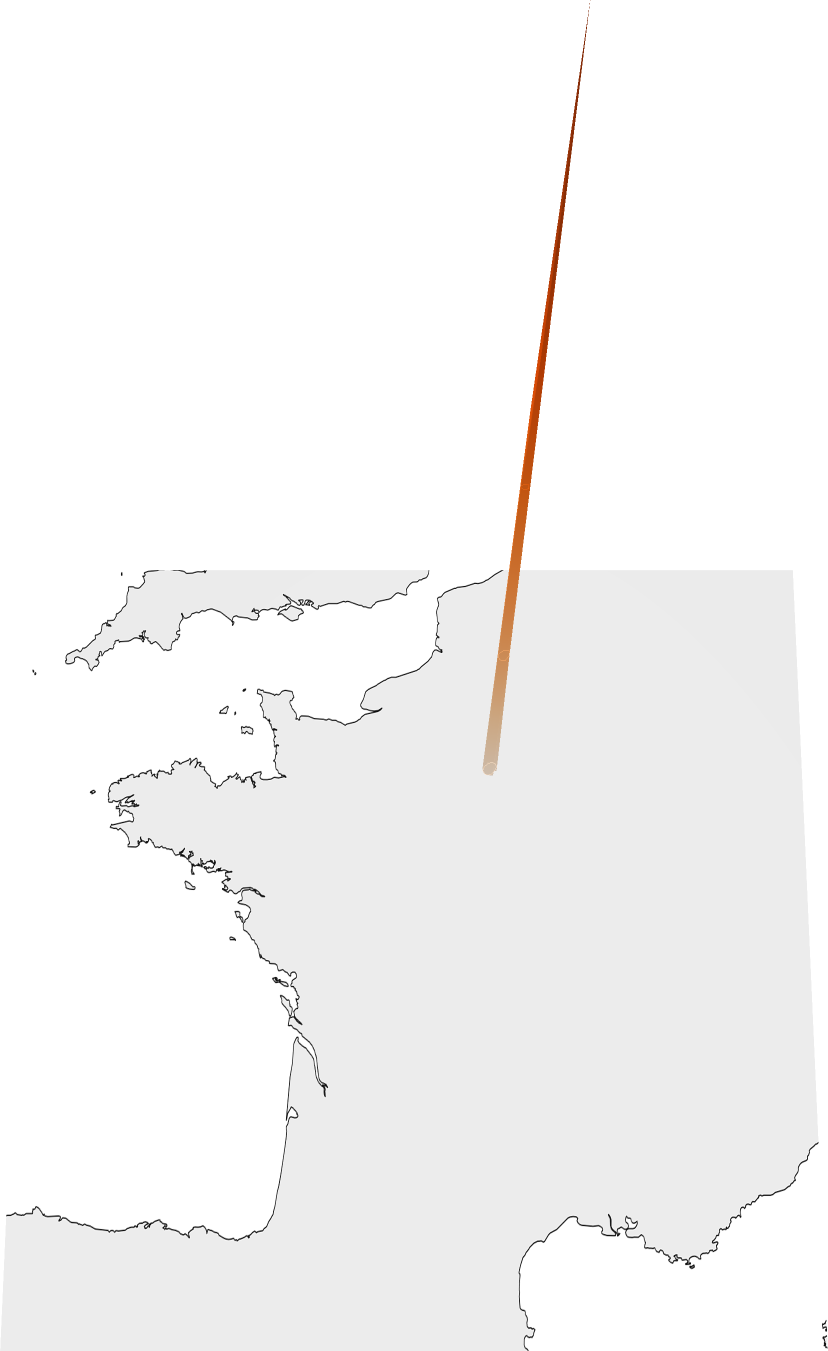
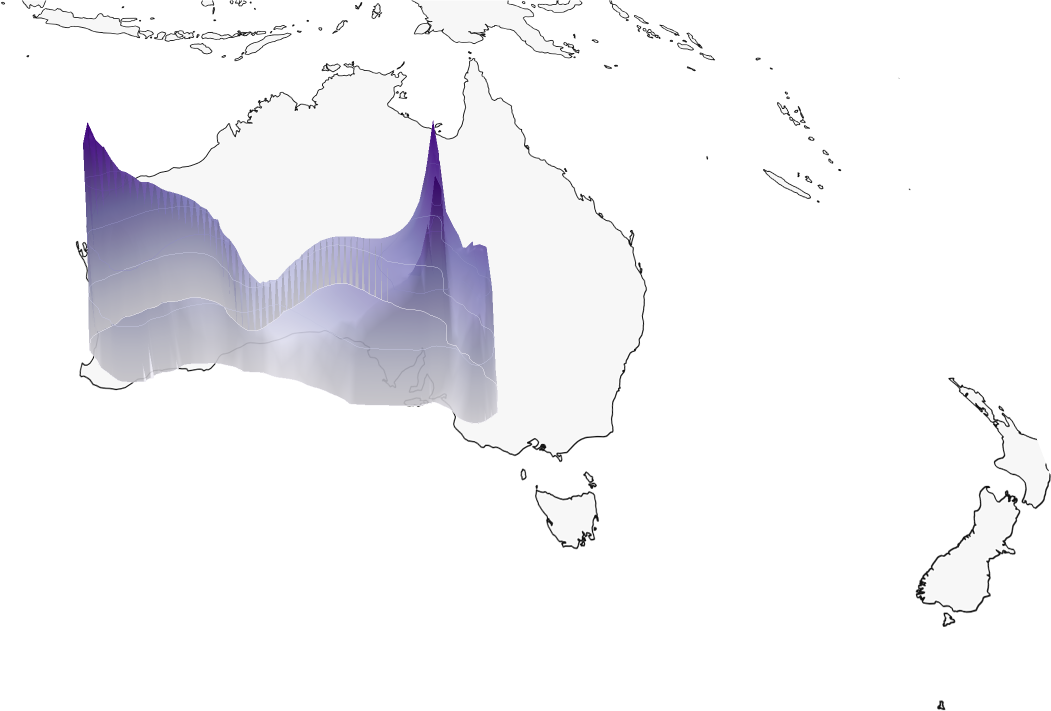
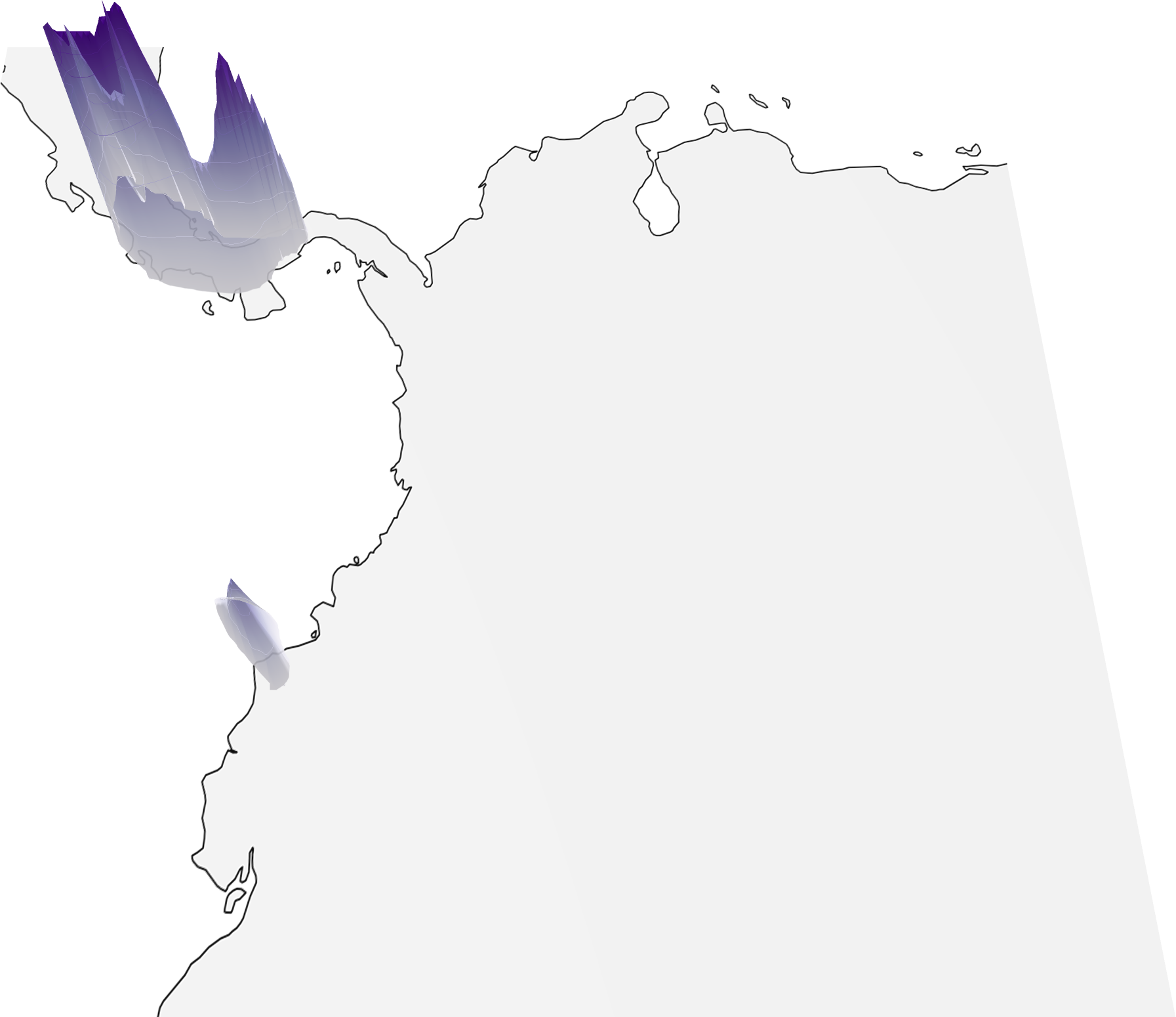
Sample Predictions




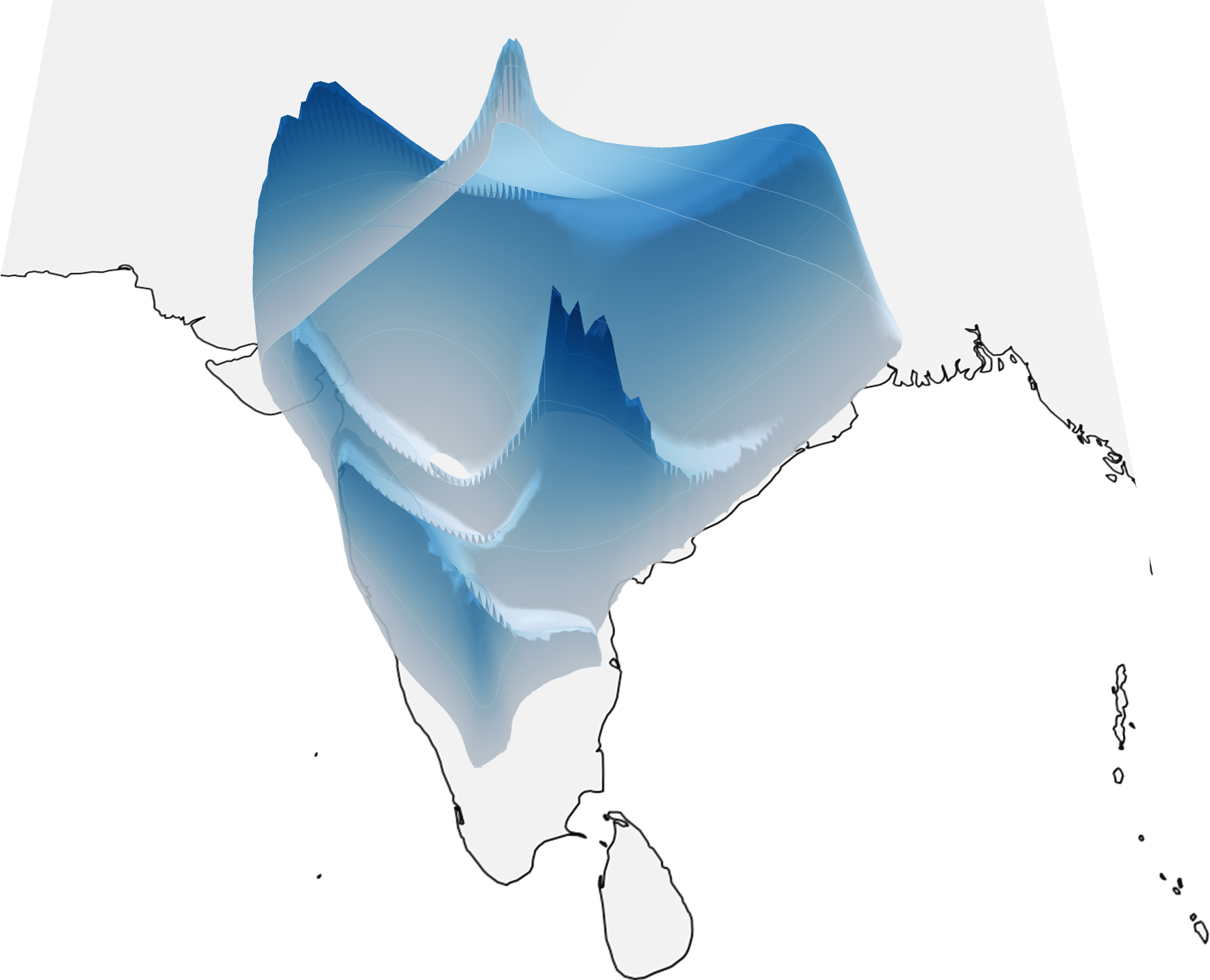

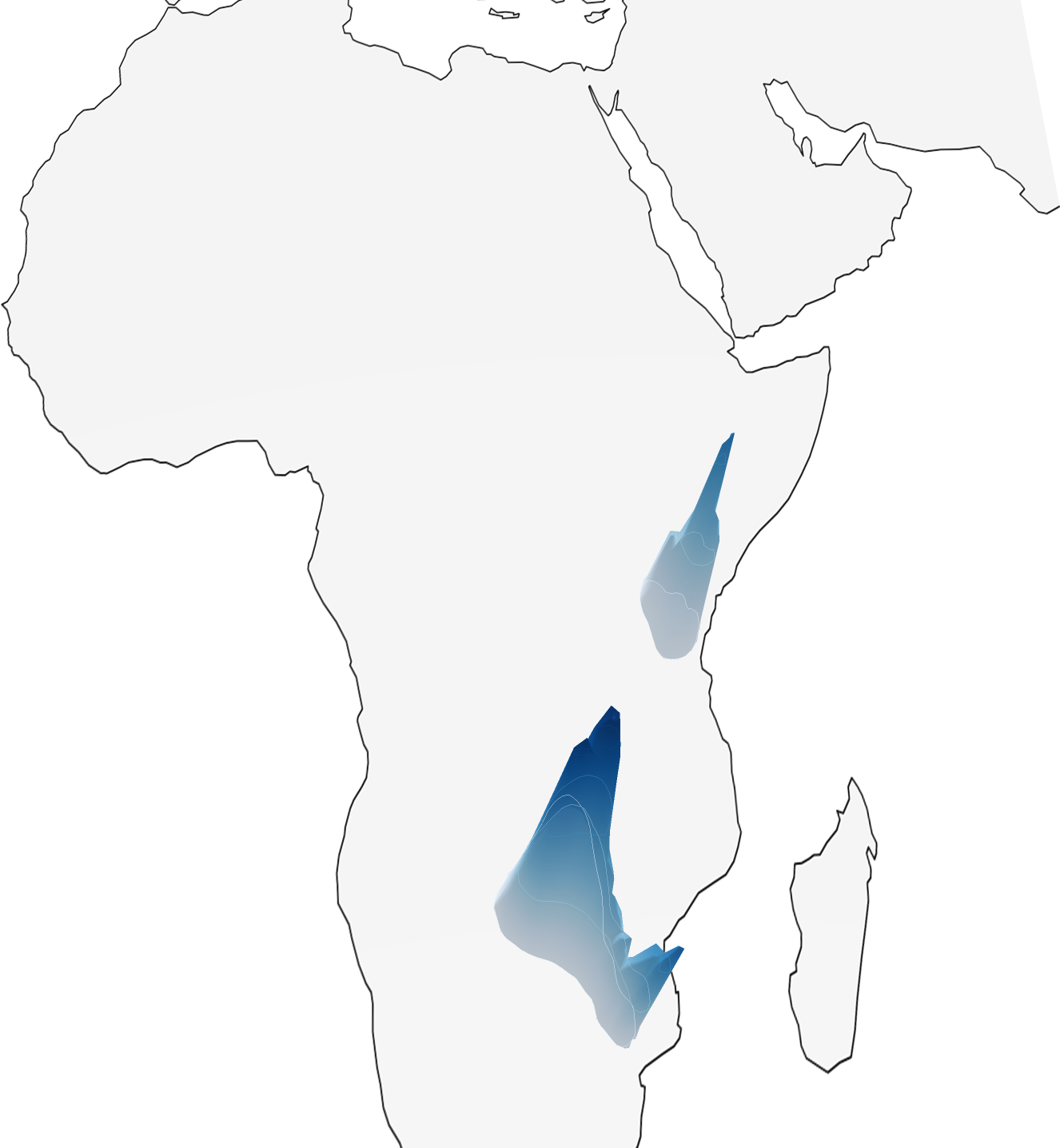

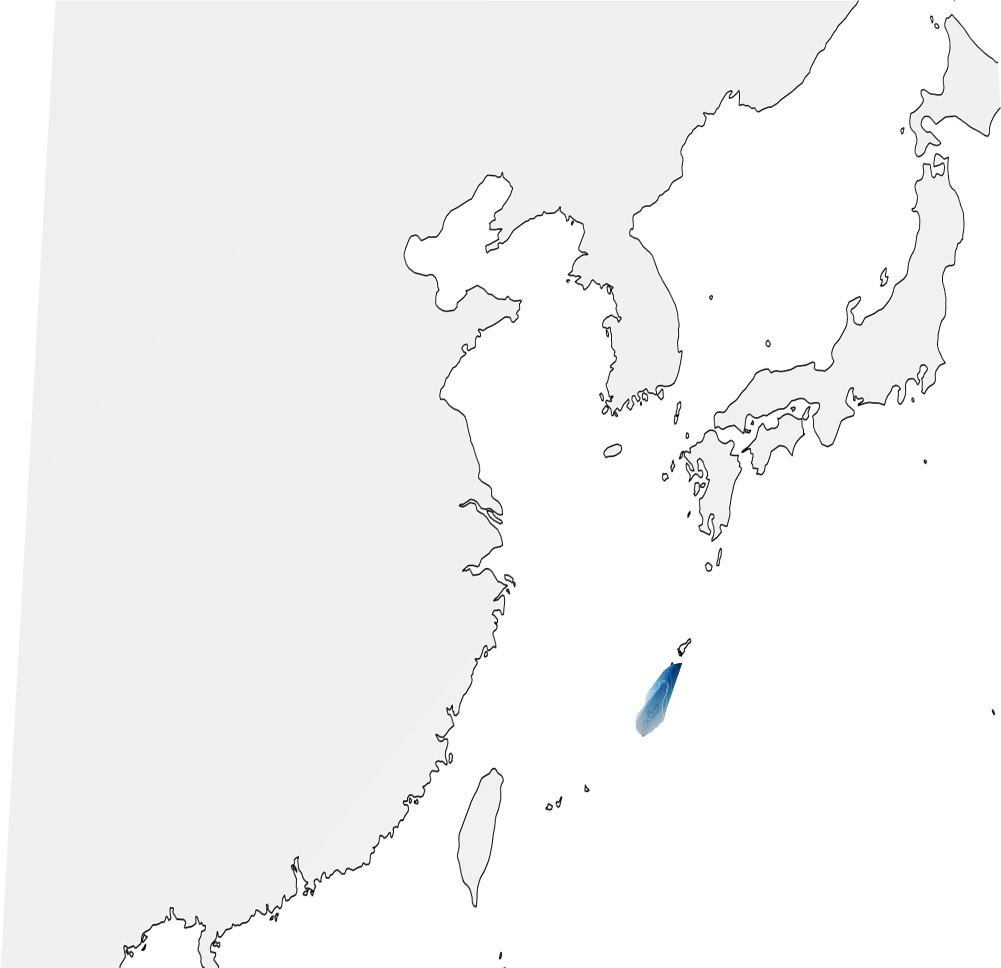

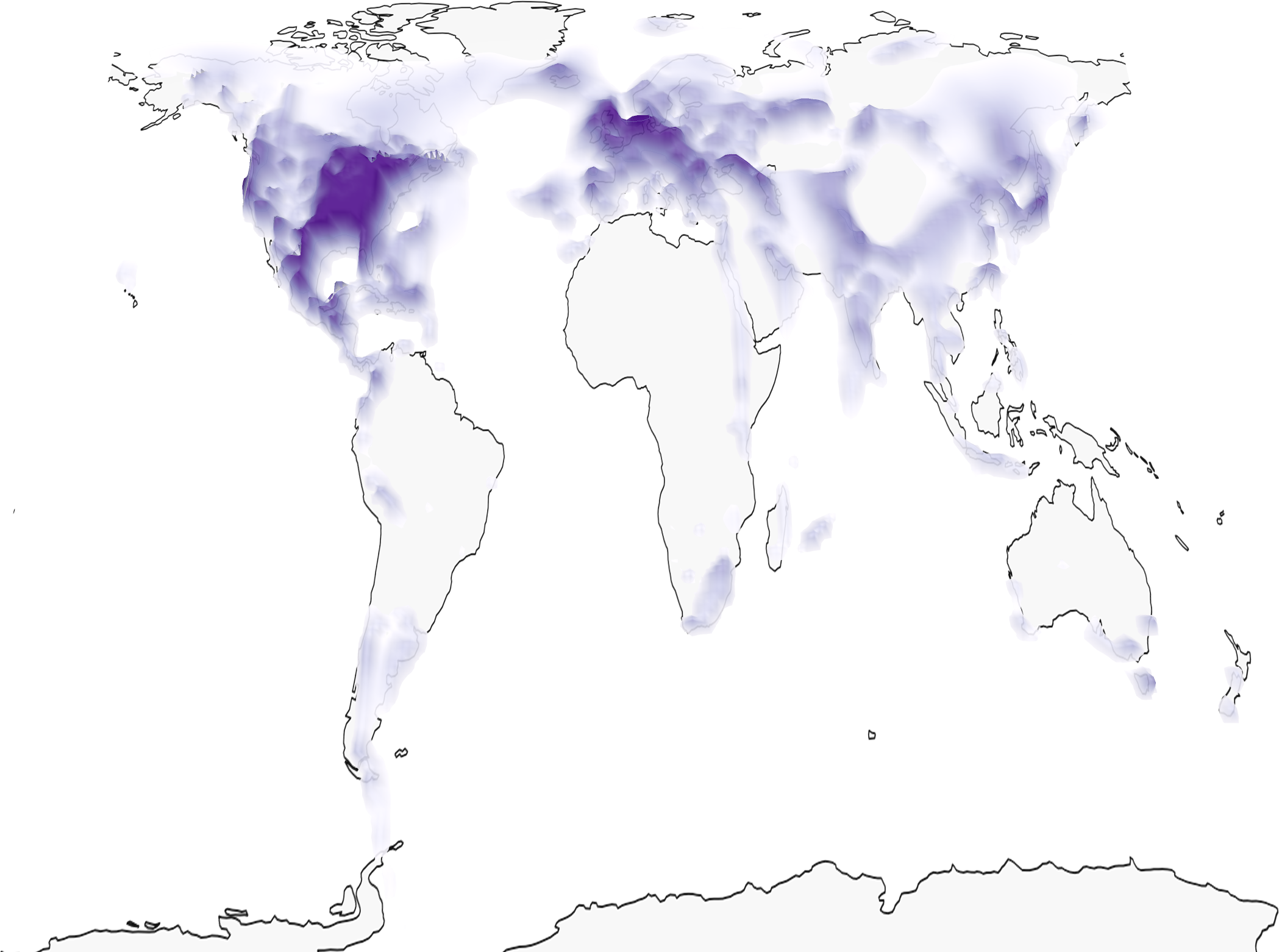


Pipeline
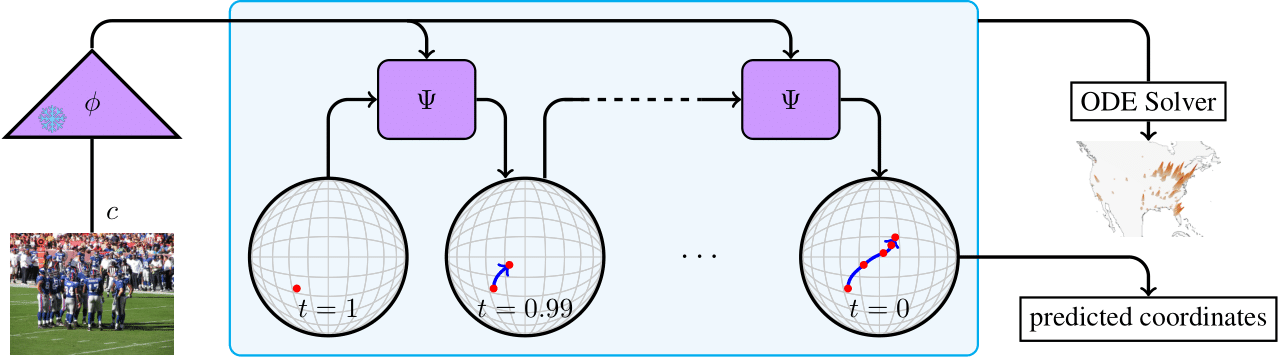
Our model operates in three main steps:
- A vision encoder Φ extracts features from the input image
- A conditional flow matching model Ψ progressively denoises coordinates on the Earth's surface by predicting velocity fields at each timestep
- An ODE solver integrates these velocity fields to obtain the final location distribution
The denoising process operates directly on the Earth's surface using Riemannian flow matching, which ensures that all intermediate points remain valid geographical coordinates.
The model can handle location ambiguity through its probabilistic predictions - when an image could have been taken in multiple locations (like a football field), the model outputs a multi-modal distribution covering all plausible locations.
Demo
Bibtex
@article{dufour2024world80timestepsgenerative,
title ={Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation},
author ={Nicolas Dufour and David Picard and Vicky Kalogeiton and Loic Landrieu},
year ={2024},
eprint ={2412.06781},
archivePrefix ={arXiv},
}
Acknowledgements
This work was supported by ANR project TOSAI ANR-20-IADJ-0009, and was granted access to the HPC resources of IDRIS under the allocation 2024-AD011015664 made by GENCI. We would like to thank Julie Mordacq, Elliot Vincent, and Yohann Perron for their helpful feedback.